
前言
随着 AI 技术的飞速发展,本地部署 AI 模型已经成为越来越多开发者和创作者的刚需。ComfyUI 是目前最强大的 Stable Diffusion 图像生成工作流工具,而 vLLM 则是性能顶尖的大语言模型推理引擎。本文将手把手教你如何在 Ubuntu 24.04 LTS 上同时搭建这两个 AI 利器,打造属于自己的本地 AI 工作站。
📋 环境要求
在开始之前,请确保你的硬件和软件满足以下要求:
| 项目 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Ubuntu 24.04 LTS | Ubuntu 24.04 LTS Server |
| GPU | NVIDIA GPU(CUDA 3.5+) | RTX 4090 / A100 (24GB+ VRAM) |
| 内存 | 16GB | 32GB 或更多 |
| 硬盘 | 50GB 可用空间 | 200GB+ SSD(模型文件较大) |
| Python | 3.10+ | 3.12 或 3.13 |
🔧 第一步:系统基础环境准备
1.1 更新系统
首先确保系统是最新的:
sudo apt update && sudo apt upgrade -y
sudo apt install -y git python3 python3-pip python3-venv python3-dev build-essential libgl1 wget1.2 安装 NVIDIA 驱动
这是最关键的一步!没有正确的 GPU 驱动,ComfyUI 和 vLLM 都无法发挥 GPU 加速的能力。
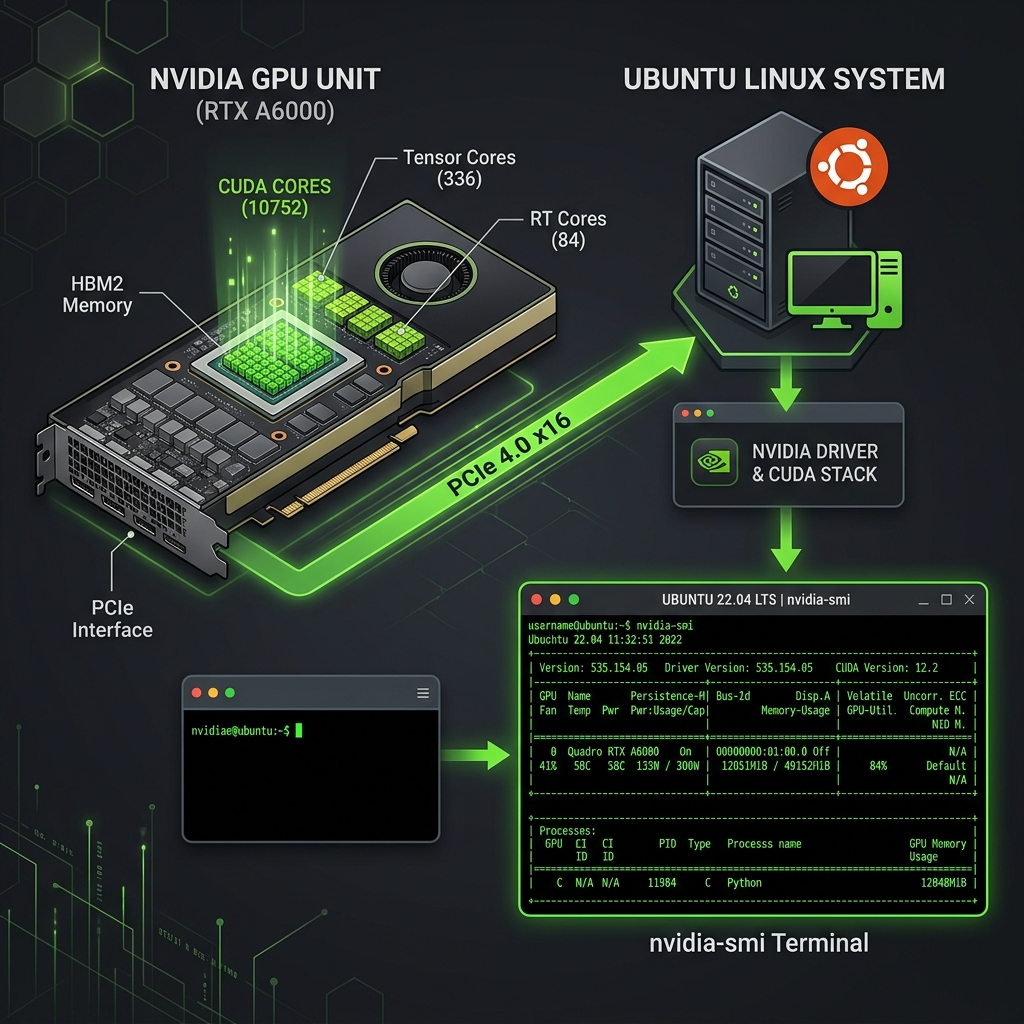
# 查看可用的 NVIDIA 驱动版本
sudo ubuntu-drivers list --gpgpu
# 安装推荐的驱动(以 580 系列为例)
sudo ubuntu-drivers install --gpgpu nvidia:580-server
# 重启系统
sudo reboot重启后验证驱动安装:
nvidia-smi如果看到类似下面的输出,说明驱动安装成功:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 580.xx.xx Driver Version: 580.xx.xx CUDA Version: 13.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | N/A |
| 0% 35C P8 10W / 350W | 0MiB / 24576MiB | 0% Default |
+-------------------------------+----------------------+----------------------+💡 提示:如果你的服务器已经预装了 NVIDIA 驱动,可以跳过这一步,直接运行
nvidia-smi检查即可。
🎨 第二步:安装 ComfyUI
ComfyUI 是一个基于节点的 Stable Diffusion 图像生成界面,它的工作流设计让你可以灵活地组合各种 AI 模型和处理节点,实现复杂的图像生成流程。
方法一:使用 Comfy CLI(推荐)
Comfy CLI 是官方提供的命令行管理工具,可以一键安装和管理 ComfyUI:
# 创建工作目录
mkdir ~/ComfyUI_install && cd ~/ComfyUI_install
# 创建 Python 虚拟环境
python3 -m venv venv
source venv/bin/activate
# 安装 Comfy CLI
pip install comfy-cli
# 一键安装 ComfyUI
comfy install
# 启动 ComfyUI
comfy launch -- --listen 0.0.0.0方法二:手动安装(从源码)
如果你喜欢手动控制每一步:
# 克隆仓库
git clone https://github.com/comfyanonymous/ComfyUI.git ~/ComfyUI
cd ~/ComfyUI
# 创建虚拟环境
python3 -m venv .venv
source .venv/bin/activate
# 升级 pip
pip install --upgrade pip wheel
# 安装 PyTorch(CUDA 13.0 版本)
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu130
# 如果是较旧的 GPU(10 系列),使用 CUDA 12.6:
# pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu126
# 安装 ComfyUI 依赖
pip install -r requirements.txt启动 ComfyUI
# 激活虚拟环境(如果尚未激活)
source ~/ComfyUI/.venv/bin/activate
# 启动,允许局域网访问
python main.py --listen 0.0.0.0启动后访问 http://你的服务器IP:8188 即可看到 ComfyUI 的界面。
下载模型
ComfyUI 本身不自带模型,你需要手动下载。以下是一些常用模型的存放路径:
# Stable Diffusion 检查点模型放到这里
~/ComfyUI/models/checkpoints/
# VAE 模型
~/ComfyUI/models/vae/
# LoRA 模型
~/ComfyUI/models/loras/
# ControlNet 模型
~/ComfyUI/models/controlnet/推荐从 HuggingFace 或 CivitAI 下载模型。
设置开机自启(可选)
使用 systemd 服务让 ComfyUI 开机自动运行:
sudo tee /etc/systemd/system/comfyui.service << 'EOF'
[Unit]
Description=ComfyUI Service
After=network.target
[Service]
Type=simple
User=你的用户名
WorkingDirectory=/home/你的用户名/ComfyUI
ExecStart=/home/你的用户名/ComfyUI/.venv/bin/python main.py --listen 0.0.0.0
Restart=on-failure
RestartSec=10
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable comfyui
sudo systemctl start comfyui🚀 第三步:安装 vLLM
vLLM 是一个高性能的大语言模型(LLM)推理和服务引擎,支持 PagedAttention 技术,能够以极高的吞吐量运行各种开源 LLM,如 Qwen、Llama、Gemma 等。
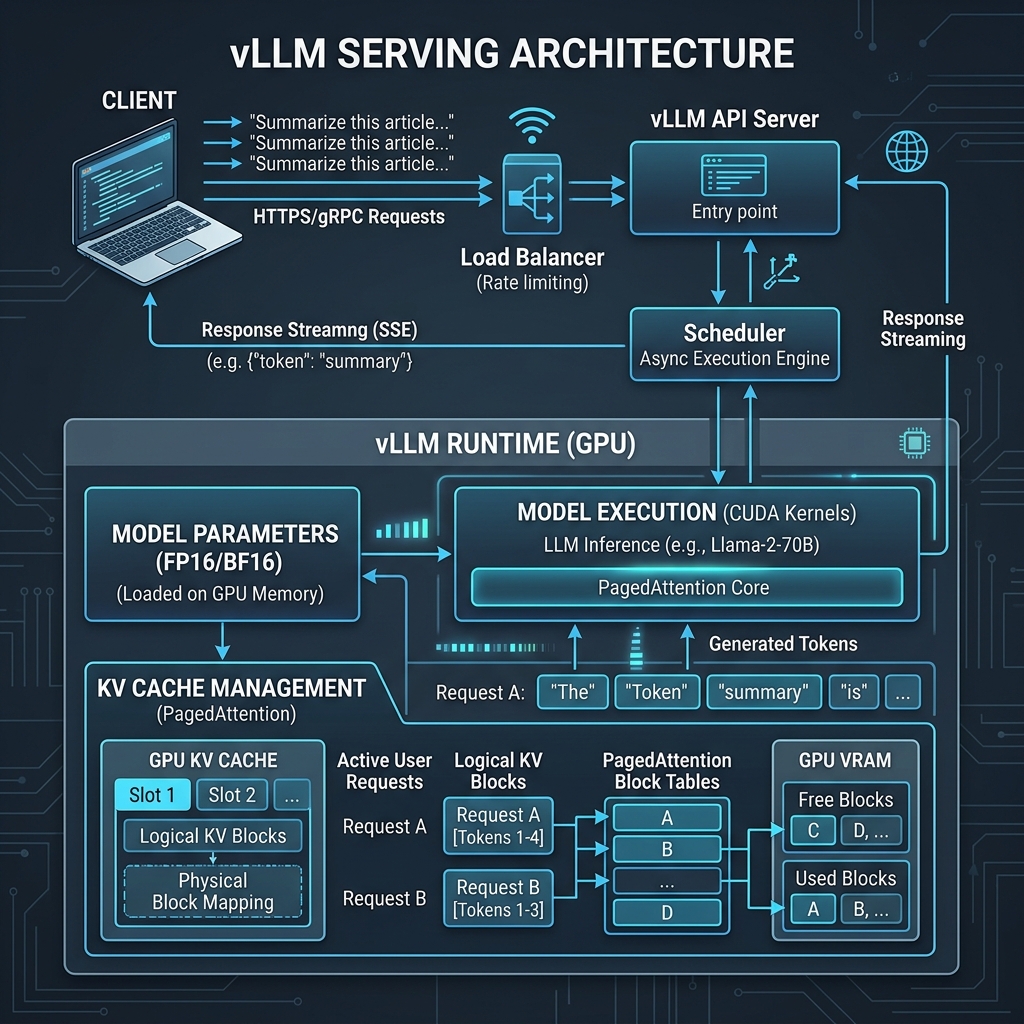
3.1 安装 uv 包管理器(推荐)
uv 是一个极速的 Python 包管理工具,比传统的 pip 快 10-100 倍:
# 安装 uv
wget -qO- https://astral.sh/uv/install.sh | sh
source $HOME/.cargo/env3.2 创建虚拟环境并安装 vLLM
# 创建专用目录
mkdir ~/vllm-service && cd ~/vllm-service
# 使用 uv 创建虚拟环境
uv venv --python 3.12
source .venv/bin/activate
# 安装 vLLM(自动检测 CUDA 版本)
uv pip install vllm --torch-backend=auto如果没有安装 uv,也可以用传统的 pip 方式:
python3 -m venv ~/vllm-service/.venv
source ~/vllm-service/.venv/bin/activate
pip install vllm3.3 验证安装
python3 -c "import vllm; print(f'vLLM version: {vllm.__version__}')"3.4 启动 vLLM 服务
vLLM 可以启动一个兼容 OpenAI API 格式的推理服务器:
# 以 Qwen2.5-7B 模型为例
vllm serve Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--gpu-memory-utilization 0.85 \
--max-model-len 8192启动后,你可以通过以下方式测试 API:
# 测试对话接口
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己"}
],
"temperature": 0.7,
"max_tokens": 512
}'3.5 vLLM 常用参数说明
| 参数 | 说明 | 示例值 |
|---|---|---|
--host |
监听地址 | 0.0.0.0 |
--port |
监听端口 | 8000 |
--gpu-memory-utilization |
GPU 显存使用比例 | 0.85 |
--max-model-len |
最大上下文长度 | 8192 |
--quantization |
量化方式(节省显存) | awq / gptq / fp8 |
--tensor-parallel-size |
多 GPU 并行数 | 2(双卡时) |
3.6 设置开机自启(可选)
sudo tee /etc/systemd/system/vllm.service << 'EOF'
[Unit]
Description=vLLM Inference Server
After=network.target
[Service]
Type=simple
User=你的用户名
WorkingDirectory=/home/你的用户名/vllm-service
ExecStart=/home/你的用户名/vllm-service/.venv/bin/vllm serve Qwen/Qwen2.5-7B-Instruct --host 0.0.0.0 --port 8000 --gpu-memory-utilization 0.85
Restart=on-failure
RestartSec=10
Environment=HUGGING_FACE_HUB_TOKEN=你的token
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable vllm
sudo systemctl start vllm⚙️ 第四步:ComfyUI + vLLM 联动(进阶玩法)
你可以将 vLLM 和 ComfyUI 结合使用,实现 “文字描述 → AI 自动扩写 Prompt → 生成图片” 的全自动工作流。
思路如下:
- 用 vLLM 部署一个 LLM(如 Qwen2.5),通过 API 接收简短描述,自动扩展为详细的图片生成 Prompt
- 将扩展后的 Prompt 传递给 ComfyUI 的 API 接口
- ComfyUI 根据 Prompt 自动生成高质量图片
这种组合在批量生成素材、设计 AI 创作工作流等场景中非常实用!
🛡️ 常见问题排查
Q1: nvidia-smi 报错 “NVIDIA-SMI has failed”
解决方案:重新安装驱动,或者检查内核版本是否匹配:
sudo apt install --reinstall nvidia-driver-580-server
sudo rebootQ2: ComfyUI 启动后 CUDA out of memory
使用低显存模式启动:
python main.py --listen 0.0.0.0 --lowvramQ3: vLLM 安装时报错 torch 版本不兼容
指定 CUDA 后端安装:
uv pip install vllm --torch-backend=cu126Q4: 如何让 ComfyUI 和 vLLM 同时运行不冲突?
如果只有一张 GPU,建议:
- 为 vLLM 限制显存使用:
--gpu-memory-utilization 0.5 - 为 ComfyUI 使用
--lowvram模式 - 或者只在需要时启动其中一个服务
📝 总结
通过本教程,你已经成功在 Ubuntu 24.04 上搭建了:
- ✅ ComfyUI:强大的 AI 图像生成工作流平台
- ✅ vLLM:高性能大语言模型推理引擎
这两个工具的组合,让你在本地拥有了一个功能完备的 AI 工作站。无论是生成精美的 AI 艺术作品,还是部署自己的聊天机器人,都可以轻松实现。祝你玩得愉快!🎉
用ai自动写的,我全程没干预。